So I built this new library called edgartools for working with SEC Edgar filings. You can use it to download listing of filings, or download single filings. It also parses XML, XBRL and JSON for you so you can work with filings as structured data with tools like pandas and arrow.
 dgunning
dgunningSo basically it speeds up your analytics workflow. What's more, you can use SQL to work with filings, using DuckDB, a new in embedded database that's become very popular for analytics.
Let's say you want to know the number of common shares issued for Snowflake (SNOW). You would get the latest 10-Q or 10-K filing and find the CommonSharesIssued value from it. And this is how you could do it in the library.
from edgar import Company
(Company.for_ticker("SNOW")
.get_filings(form=["10-Q", "10-K"])
.latest()
.xbrl()
.to_duckdb().execute(
"""select fact, value, units, end_date from facts
where fact = 'CommonStockSharesIssued'
order by end_date desc limit 1
"""
).df()
)You see how the library encapsulates ways of working with Edgar, including finding companies, getting the latest filings, and downloading documents and data.
But there's SQL in there too, which means there has to be structured data, not just the HTML text we see when we look at a raw edgar filing. That's where XBRL comes it - with XBRL (eXtensible Business Markup Language) the SEC allows for documents that contain structured data about a company and filings. This structured data is XML, but it can also pretty easily be converted into tabular data which can then be queried using database tools. And with DuckDB that becomes pretty easy.
pip install edgartoolsOther tools for working with Edgar
There are of course a bunch of other tools for working with SEC filings.
Libraries for working with SEC filings
There are a lot of libraries for working with SEC filings - it's a crowded field.
edgartools is easier to use, more modern and provide more features. That facts.
Speaking of facts, did you know that you can get a historical dataset of facts for a company containing the data provided to the SEC over the years? That would be pretty useful, and easy to get with edgartools.
(Company.for_ticker("SNOW")
.get_facts()
.to_pandas()
.filter(['namespace', 'fact', 'val', 'form'])
.sort_values(['filed'], ascending=[False])
).style.format({"val": "{:,.0f}"}).hide(axis='index')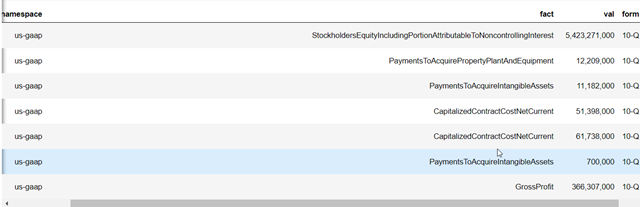
So edgartools let you work with company filings as text, HTML but also structured data, which is what you actually want to do data analysis.
Libraries that parse XBRL
There are libraries for parsing XBRL files - notably
These libraries are both good at parsing XBRL XML documents. These documents can be pretty complicated and expressive, particularly as companies often use the base XBRL schema plus their own custom schemas for representing their business logic. And so these libraries use a document oriented approach to parsing XBRL in order to fully resolve related entities and the data stored within the documents.
edgartools uses a data oriented approach and will parse the XBRL document only to the extent that it can create structured dataset like dataframes and or DB tables. This means we don't download related schema files and so the library is a lot faster if what you want is the data. And it turns out that this approach still gets you useful data.
Conclusion
Try the library, and make sure to leave a star on the Github repository if you find it useful.